publications
2026
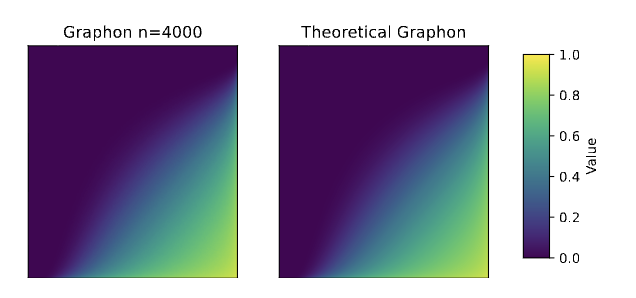 Pruning at Initialisation through the lens of Graphon Limit: Convergence, Expressivity, and GeneralisationHoang Pham, The-Anh Ta, and Long Tran-Thanhpreprint, 2026
Pruning at Initialisation through the lens of Graphon Limit: Convergence, Expressivity, and GeneralisationHoang Pham, The-Anh Ta, and Long Tran-Thanhpreprint, 2026Pruning at Initialisation methods discover sparse, trainable subnetworks before training, but their theoretical mechanisms remain elusive. Existing analyses are often limited to finite-width statistics, lacking a rigorous characterisation of the global sparsity patterns that emerge as networks grow large. In this work, we connect discrete pruning heuristics to graph limit theory via graphons, establishing the graphon limit of PaI masks. We introduce a Factorised Saliency Model that encompasses popular pruning criteria and prove that, under regularity conditions, the discrete masks generated by these algorithms converge to deterministic bipartite graphons. This limit framework establishes a novel topological taxonomy for sparse networks: while unstructured methods (e.g., Random, Magnitude) converge to homogeneous graphons representing uniform connectivity, data-driven methods (e.g., SNIP, GraSP) converge to heterogeneous graphons that encode implicit feature selection. Leveraging this continuous characterisation, we derive two fundamental theoretical results: (i) a Universal Approximation Theorem for sparse networks that depends only on the intrinsic dimension of active coordinate subspaces; and (ii) a Graphon-NTK generalisation bound demonstrating how the limit graphon modulates the kernel geometry to align with informative features. Our results transform the study of sparse neural networks from combinatorial graph problems into a rigorous framework of continuous operators, offering a new mechanism for analysing expressivity and generalisation in sparse neural networks.
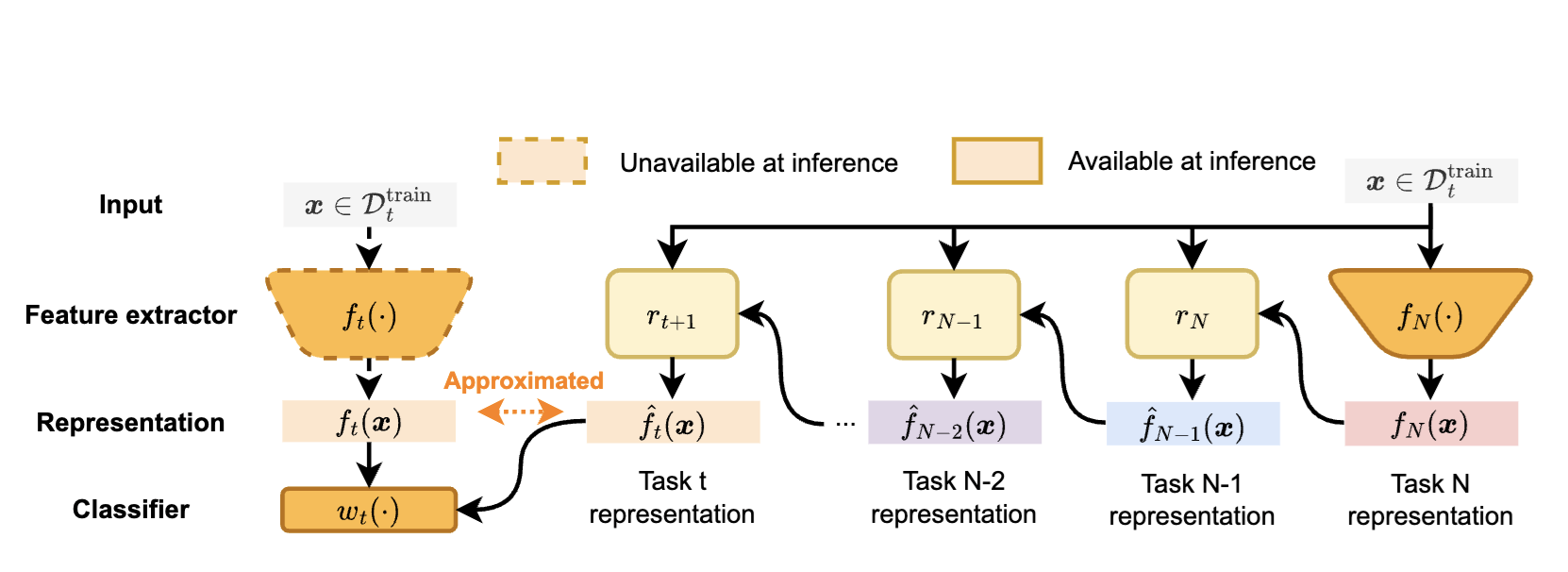 Retrospective Feature Estimation for Continual LearningNghia D. Nguyen, Hieu Trung Nguyen, Ang Li, and 3 more authorsTransactions on Machine Learning Research, 2026Featured Certification, J2C Certification
Retrospective Feature Estimation for Continual LearningNghia D. Nguyen, Hieu Trung Nguyen, Ang Li, and 3 more authorsTransactions on Machine Learning Research, 2026Featured Certification, J2C CertificationThe intrinsic capability to continuously learn a changing data stream is a desideratum of deep neural networks (DNNs). However, current DNNs suffer from catastrophic forgetting, which interferes with remembering past knowledge. To mitigate this issue, existing Continual Learning (CL) approaches often retain exemplars for replay, regularize learning, or allocate dedicated capacity for new tasks. This paper investigates an unexplored direction for CL called Retrospective Feature Estimation (RFE). RFE learns to reverse feature changes by aligning the features from the current trained DNN backward to the feature space of the old task, where performing predictions is easier. This retrospective process utilizes a chain of small feature mapping networks called retrospector modules. Empirical experiments on several CL benchmarks, including CIFAR10, CIFAR100, and Tiny ImageNet, demonstrate the effectiveness and potential of this novel CL direction compared to existing representative CL methods, motivating further research into retrospective mechanisms as a principled alternative for mitigating catastrophic forgetting in CL


2025
- The Graphon Limit Hypothesis: Understanding Neural Network Pruning via Infinite Width AnalysisHoang Pham, The-Anh Ta, Tom Jacobs, and 2 more authorsAdvances in Neural Information Processing Systems, 2025Spotlight Presentation
Sparse neural networks promise efficiency, yet training them effectively remains a fundamental challenge. Despite advances in pruning methods that create sparse architectures, understanding why some sparse structures are better trainable than others with the same level of sparsity remains poorly understood. Aiming to develop a systematic approach to this fundamental problem, we propose a novel theoretical framework based on the theory of graph limits, particularly graphons, that characterizes sparse neural networks in the infinite-width regime. Our key insight is that connectivity patterns of sparse neural networks induced by pruning methods converge to specific graphons as networks’ width tends to infinity, which encodes implicit structural biases of different pruning methods. We postulate the Graphon Limit Hypothesis and provide empirical evidence to support it. Leveraging this graphon representation, we derive a Graphon Neural Tangent Kernel (Graphon NTK) to study the training dynamics of sparse networks in the infinite width limit. Graphon NTK provides a general framework for the theoretical analysis of sparse networks. We empirically show that the spectral analysis of Graphon NTK correlates with observed training dynamics of sparse networks, explaining the varying convergence behaviours of different pruning methods. Our framework provides theoretical insights into the impact of connectivity patterns on the trainability of various sparse network architectures.
- DPaI: Differentiable Pruning at Initialization with Node-Path Balance PrincipleLichuan Xiang, Quan Nguyen-Tri, Lan-Cuong Nguyen, and 4 more authorsThe Thirteenth International Conference on Learning Representations, 2025
Pruning at Initialization (PaI) is a technique in neural network optimization characterized by the proactive elimination of weights before the network’s training on designated tasks. This innovative strategy potentially reduces the costs for training and inference, significantly advancing computational efficiency. A key factor leading to PaI’s effectiveness is that it considers the saliency of weights in an untrained network, and prioritizes the trainability and optimization potential of the pruned subnetworks. Recent methods can effectively prevent the formation of hard-to-optimize networks, e.g. through iterative adjustments at each network layer. However, this way often results in large-scale discrete optimization problems, which could make PaI further challenging. This paper introduces a novel method, called DPaI, that involves a differentiable optimization of the pruning mask. DPaI adopts a dynamic and adaptable pruning process, allowing easier optimization processes and better solutions. More importantly, our differentiable formulation enables readily use of the existing rich body of efficient gradient-based methods for PaI. Our empirical results demonstrate that DPaI significantly outperforms current state-of-the-art PaI methods on various architectures, such as Convolutional Neural Networks and Vision-Transformers.


2024
- Flatness-aware Sequential Learning Generates Resilient BackdoorsHoang Pham, The-Anh Ta, Anh Tran, and 1 more authorProceedings of the European Conference on Computer Vision (ECCV), 2024Oral Presentation
Recently, backdoor attacks have become an emerging threat to the security of machine learning models. From the adversary’s perspective, the implanted backdoors should be resistant to defensive algorithms, but some recently proposed fine-tuning defenses can remove these backdoors with notable efficacy. This is mainly due to the catastrophic forgetting (CF) property of deep neural networks. This paper counters CF of backdoors by leveraging continual learning (CL) techniques. We begin by investigating the connectivity between a backdoored and fine-tuned model in the loss landscape. Our analysis confirms that fine-tuning defenses, especially the more advanced ones, can easily push a poisoned model out of the backdoor regions, making it forget all about the backdoors. Based on this finding, we re-formulate backdoor training through the lens of CL and propose a novel framework, named Sequential Backdoor Learning (SBL), that can generate resilient backdoors. This framework separates the backdoor poisoning process into two tasks: the first task learns a backdoored model, while the second task, based on the CL principles, moves it to a backdoored region resistant to fine-tuning. We additionally propose to seek flatter backdoor regions via a sharpness-aware minimizer in the framework, further strengthening the durability of the implanted backdoor. Finally, we demonstrate the effectiveness of our method through extensive empirical experiments on several benchmark datasets in the backdoor domain.

2023
- Towards Data-Agnostic Pruning At Initialization: What Makes a Good Sparse Mask?Hoang Pham, The-Anh Ta, Shiwei Liu, and 4 more authorsAdvances in Neural Information Processing Systems, 2023
Pruning at initialization (PaI) aims to remove weights of neural networks before training in pursuit of training efficiency besides the inference. While off-the-shelf PaI methods manage to find trainable subnetworks that outperform random pruning, their performance in terms of both accuracy and computational reduction is far from satisfactory compared to post-training pruning and the understanding of PaI is missing. For instance, recent studies show that existing PaI methods only able to find good layerwise sparsities not weights, as the discovered subnetworks are surprisingly resilient against layerwise random mask shuffling and weight re-initialization. In this paper, we study PaI from a brand-new perspective – the topology of subnetworks. In particular, we propose a principled framework for analyzing the performance of Pruning and Initialization (PaI) methods with two quantities, namely, the number of effective paths and effective nodes. These quantities allow for a more comprehensive understanding of PaI methods, giving us an accurate assessment of different subnetworks at initialization. We systematically analyze the behavior of various PaI methods through our framework and observe a guiding principle for constructing effective subnetworks: at a specific sparsity, the top-performing subnetwork always presents a good balance between the number of effective nodes and the number of effective paths. Inspired by this observation, we present a novel data-agnostic pruning method by solving a multi-objective optimization problem. By conducting extensive experiments across different architectures and datasets, our results demonstrate that our approach outperforms state-of-the-art PaI methods while it is able to discover subnetworks that have much lower inference FLOPs (up to 3.4x)

2022
- Journal
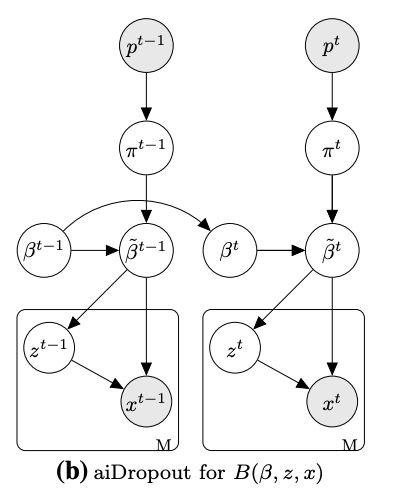 Adaptive infinite dropout for noisy and sparse data streamsHa Nguyen*, Hoang Pham*, Son Nguyen, and 2 more authorsMachine Learning, 2022
Adaptive infinite dropout for noisy and sparse data streamsHa Nguyen*, Hoang Pham*, Son Nguyen, and 2 more authorsMachine Learning, 2022The ability to analyze data streams, which arrive sequentially and possibly infinitely, is increasingly vital in various online applications. However, data streams pose various challenges, including sparse and noisy data as well as concept drifts, which easily mislead a learning method. This paper proposes a simple yet robust framework, called Adaptive Infinite Dropout (aiDropout), to effectively tackle these problems. Our framework uses a dropout technique in a recursive Bayesian approach in order to create a flexible mechanism for balancing between old and new information. In detail, the recursive Bayesian approach imposes a constraint on the model parameters to make a regularization term between the current and previous mini-batches. Then, dropout whose drop rate is autonomously learned can adjust the constraint to new data. Thanks to the ability to reduce overfitting and the ensemble property of Dropout, our framework obtains better generalization, thus it effectively handles undesirable effects of noise and sparsity. In particular, theoretical analyses show that aiDropout imposes a data-dependent regularization, therefore, it can adapt quickly to sudden changes from data streams. Extensive experiments show that aiDropout significantly outperforms the state-of-the-art baselines on a variety of tasks such as supervised and unsupervised learning.
- Pruning Deep Equilibrium ModelsHoang Pham*, Tuc Nguyen*, Anh Ta-The, and 2 more authorsICML 2022 Workshop on Sparse Neural Networks, 2022
- PAKDDAuxiliary local variables for improving regularization/prior approach in continual learningLinh Ngo Van*, Nam Le Hai*, Hoang Pham*, and 1 more authorPacific-Asia Conference on Knowledge Discovery and Data Mining, 2022
- PreprintHyperSparse: Specializing Parameters of Meta-Learning Models for Effective User Cold-Start RecommendationHoang Pham, Quang Pham, Dung D Le, and 1 more authorpreprint, 2022
